Claude Opus 4.7, released on April 16, 2026, is a targeted upgrade for the Claude 4 model family, tuned for advanced software engineering and professional multi-step tasks. It runs more rigorously, consistently, and autonomously than its predecessor on complex systems architecture. The headline change: it needs far less supervision on long-running workflows, thanks to better self-verification and deeper reasoning.
This release introduces the specialized "xhigh" effort level, enabling finer granular control over the trade-off between reasoning tokens and processing latency. Beyond logic, the model adds a 3x increase in high-resolution vision acuity and a more precise tokenizer for more efficient text processing. Together these let Claude Opus 4.7 work as a reliable teammate on production-level engineering, with minimal human intervention.
Source: Claude Opus 4.7 — Anthropic
What is Claude Opus 4.7 and where can you use it?
Claude Opus 4.7 is a deliberate mid-cycle upgrade to Opus 4.6, slotted into Anthropic's model lineup as the rigorous engineering option.
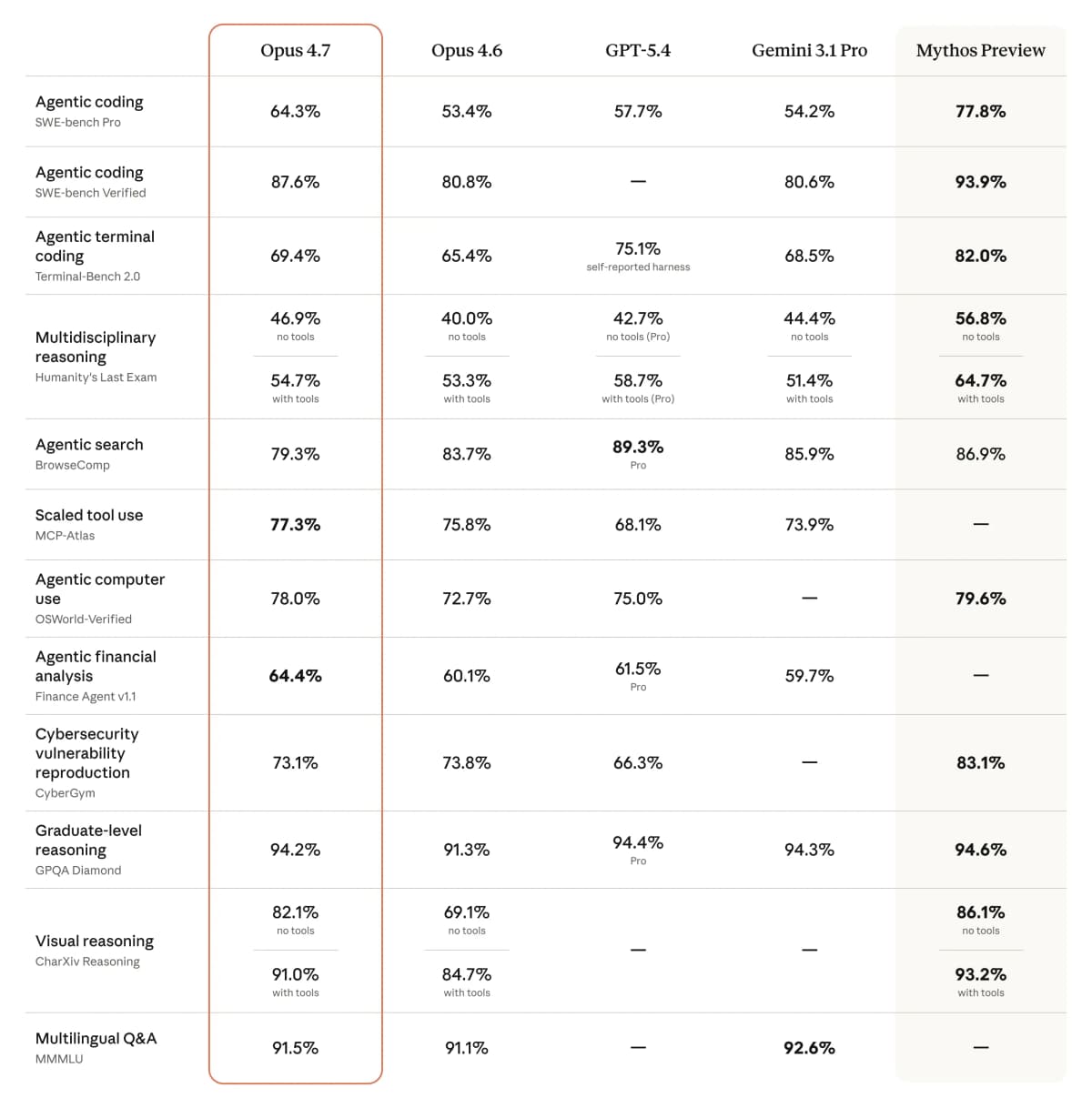
Claude Mythos Preview is still the more broadly capable frontier model, but its availability is restricted because of heavier safety and alignment testing. Opus 4.7, by contrast, is built for general availability — a stable, accessible path for organizations to run high-autonomy agents without the specialized access the Mythos tier requires.
The model is integrated across the complete Claude product suite, ensuring availability for users on Pro, Max, Team, and Enterprise plans. For systems architects and developers, the model is accessible via the Claude API using the model identifier claude-opus-4-7. It is also supported through infrastructure partners, including Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry. Pricing holds at $5 per 1 million input tokens and $25 per 1 million output tokens. Because pricing is unchanged, teams can move up an intelligence tier without redoing their API cost projections.
What is the new xhigh effort level and how do the five effort levels work?
Effort control gives systems architects a dial for the compute spent on a given query, balancing reasoning depth against execution time. Claude Opus 4.7 uses adaptive thinking — turn by turn, the model decides whether a prompt needs a reasoning stage or a direct answer. Simple lookups don't waste thinking tokens; hard logic problems get the cognitive overhead they need.
There are now five distinct effort levels: low, medium, high, xhigh, and max. The "xhigh" (extra high) level is the flagship addition for this version, positioned as a new default for Claude Code. It is specifically calibrated for difficult architectural tasks that require more rigor than the high setting but do not necessitate the full latency of the max setting. Benchmark data shows that a low-effort Opus 4.7 request is roughly as capable as a medium-effort Opus 4.6 request — a real jump in baseline efficiency. The five tiers let you allocate resources more precisely, replacing the old binary thinking toggle with a graded spectrum of effort.
What else changed vs Opus 4.6?
The transition to Claude Opus 4.7 provides a quality-of-life leap for autonomous workflows by addressing the "looping" and "hallucination" issues common in long-horizon tasks. The model has been re-tuned to prioritize role fidelity and sustained reasoning over hours of continuous execution.
Advanced coding and autonomy
In software engineering evaluations, Opus 4.7 posts a 13% lift on a 93-task coding benchmark. It also resolved four specific tasks that neither Opus 4.6 nor Sonnet 4.6 could complete. On the Rakuten-SWE-Bench, the model resolved three times as many production-level tasks as Opus 4.6, with double-digit gains in both Code Quality and Test Quality. The reason is a new behavior: the model runs proofs on systems code before starting work and catches its own logical faults during the planning phase. This "proof-before-action" approach cuts down on meaningless wrapper functions and fallback scaffolding.
Multimodal and vision enhancements
The vision subsystem grew substantially, now supporting images up to 2,576 pixels on the long edge (about 3.75 megapixels) — a 3x increase in detail resolution. On the XBOW visual-acuity benchmark, Opus 4.7 improved its score to 98.5%, up from 54.5% for Opus 4.6. That jump lets the model read dense screenshots, chemical structures, and complex technical diagrams with high fidelity. Higher resolution consumes more tokens, so systems architects should consider downsampling images in the application layer when pixel-perfect detail isn't needed for a given task.
Tokenization and task budgets
The model introduces "task budgets" in public beta, a feature that allows developers to guide token expenditure across long agentic runs. This is accompanied by an updated tokenizer that processes text more efficiently but changes mapping ratios. For the same input string, the new tokenizer may generate between 1.0x and 1.35x more tokens depending on the content. The model also tends to produce more reasoning tokens at higher effort levels during the later turns of an agentic session. Internal coding evaluations show the net effect on quality-per-token is favorable, but developers still have to handle the resulting shifts in API behavior.
What breaking API changes must developers handle?
Migrating to Claude Opus 4.7 means re-checking your prompt harnesses, because the model now follows instructions far more literally. Where Opus 4.6 sometimes read prompts loosely or bypassed specific constraints, Opus 4.7 takes them at face value. Prompts that leaned on the old "creative slack" or imprecise phrasing may now behave unexpectedly, so existing production libraries will need re-tuning.
There are new constraints on sampling, too. In any thinking mode, the model no longer supports the traditional parameters temperature, top_p, or top_k — including them in a request now returns a 400 error. Developers should also integrate the new stop_details object in refusal responses. It gives declined requests a machine-readable category, so applications can tell a safety-triggered refusal apart from an operational stop. These changes make the model more predictable in production, though its use still depends on specific risk profiles.
When is Opus 4.7 not the right choice?
For all its technical gains, Opus 4.7 isn't the right pick for every deployment. Organizations that need the absolute maximum in raw reasoning should still use Claude Mythos Preview, since Opus 4.7 is intentionally less broadly capable than the Mythos class. Opus 4.7 is the standardized, reliable model for engineering and knowledge work — not a frontier research model.
Significant restrictions apply to cybersecurity use cases. Opus 4.7 is the first model used to test safeguards from Project Glasswing, an Anthropic initiative to manage the dual-use risks of AI in security domains. During training, the model's cyber capabilities were differentially reduced compared to Mythos Preview. The model includes automated safeguards to detect and block requests associated with prohibited or high-risk cybersecurity activities. For security professionals requiring the model for legitimate purposes—such as vulnerability research or red-teaming—the only authorized path is through the Cyber Verification Program. Standard API access will result in refusals for high-stakes security queries.
What does this mean in practice (developers / chat users / everyone)?
The practical upshot of the Opus 4.7 release is a shift in how you orchestrate AI work. With better loop resistance and graceful error recovery, the human role moves from managing one agent at a time to supervising several in parallel. The model also resists "dissonant-data traps"—cases where conflicting data points push a model to hallucinate or stall—which makes it a more resilient partner for unattended automation.
For developers, the new /ultrareview command in Claude Code gives a dedicated way to surface subtle bugs and design flaws in complex PRs. Max users now get "auto mode," which lets longer tasks run with fewer interruptions. Beyond coding, the model posted a double-digit jump in document reasoning on the OfficeQA Pro benchmark, which recorded 21% fewer errors, and it leads the GDPval-AA evaluation for economically valuable knowledge in legal and financial work. Better design judgment backs that accuracy: the model makes interface and dashboard choices that need little post-generation editing. By passing "implicit-need tests"—catching requirements the user never spelled out—Opus 4.7 earns its place as a teammate in production.