Claude Opus 4.7 là phiên bản nâng cấp chiến lược của Anthropic, được thiết kế để xử lý các bài toán kỹ thuật phần mềm chuyên sâu và các quy trình tác nhân (agentic workflows) có độ phức tạp cao. Model này mang lại sự cải thiện rõ rệt về khả năng lập trình tự chủ so với phiên bản 4.6, đồng thời tối ưu hóa thị giác máy tính để xử lý dữ liệu hình ảnh mật độ cao.
Với tư cách là bước đệm quan trọng trước khi dòng model Claude Mythos Preview cao cấp nhất được phổ biến, Claude Opus 4.7 tập trung vào tính nhất quán và khả năng tự kiểm chứng (self-verification). Model không chỉ thực thi các tác vụ dài hơi mà còn chủ động phát hiện lỗi logic trong giai đoạn lập kế hoạch, giúp giảm thiểu sự can thiệp của con người vào các hệ thống tự vận hành.
Nguồn: Claude Opus 4.7 — Anthropic
Claude Opus 4.7 là gì và dùng được ở đâu?
Claude Opus 4.7 đóng vai trò trung tâm trong lộ trình phát triển của Anthropic, được định vị là phiên bản hoàn thiện nhất của dòng Opus trước khi tiến lên kiến trúc Claude Mythos Preview.
Trong các giải pháp AI doanh nghiệp, model này ưu tiên khả năng suy luận đa bước và sự tỉ mỉ hơn là tốc độ xử lý thô.
Chi tiết kỹ thuật và triển khai:
- Model ID chính thức:
claude-opus-4-7. - Nền tảng hỗ trợ: Có sẵn trên Claude API, Amazon Bedrock và Google Cloud Vertex AI. Tại Microsoft Foundry, model bị giới hạn cửa sổ ngữ cảnh ở mức 200k token (so với mức chuẩn của hệ thống).
- Cấu trúc chi phí: Duy trì mức $5/1M input tokens và $25/1M output tokens. Việc áp dụng prompt caching có thể giúp tiết kiệm tới 90% chi phí đầu vào.
- Ngữ cảnh: Model được tối ưu để duy trì tính mạch lạc trong các phiên làm việc kéo dài nhiều giờ (long-horizon tasks), đảm bảo không mất phương hướng khi xử lý lượng lớn dữ liệu đầu vào.
Cốt lõi của sự nâng cấp này nằm ở khả năng kiểm soát tài nguyên suy nghĩ thông qua hệ thống nỗ lực linh hoạt.
Cấp độ nỗ lực xhigh mới là gì, và năm cấp độ nỗ lực hoạt động thế nào?
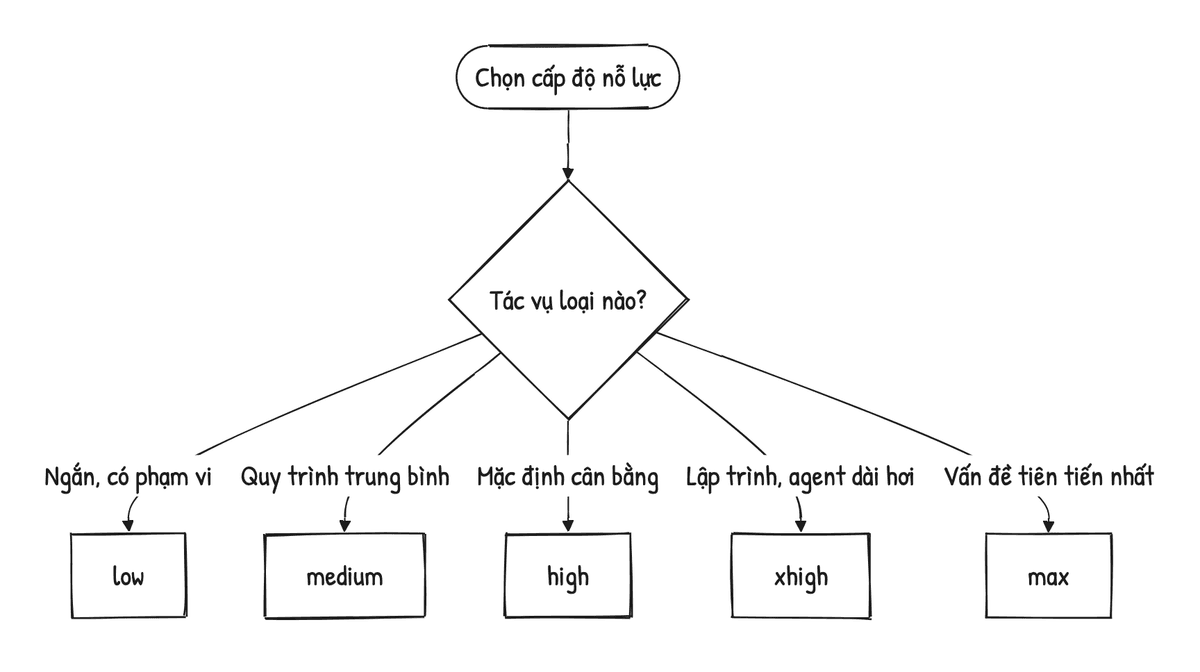
Kiểm soát nỗ lực (effort) là cơ chế thay thế cho các tham số truyền thống để tối ưu hóa sự cân bằng giữa chi phí và hiệu năng. Thay vì ép model suy nghĩ tối đa cho mọi yêu cầu, lập trình viên có thể chỉ định mức độ đầu tư trí tuệ phù hợp với độ khó của tác vụ.
Cơ chế vận hành:
- Định nghĩa xhigh (extra high): Nằm giữa
highvàmax, cấp độ này cung cấp sự gia tăng đáng kể về khả năng giải quyết lỗi logic phức tạp mà không gây ra độ trễ quá lớn như mứcmax. - 5 cấp độ nỗ lực: Bao gồm
low,medium,high,xhigh, vàmax. - Thiết lập mặc định: Trong Claude Code, mức nỗ lực mặc định đã được nâng lên
xhighđể xử lý các vấn đề code tầng sâu như race conditions hay concurrency bugs. - Cơ chế Adaptive thinking: Model tích hợp khả năng tự điều chỉnh tư duy. Với các câu hỏi đơn giản, model sẽ phản hồi trực tiếp để tiết kiệm token; với các bài toán khó, model sẽ tự kích hoạt chuỗi suy nghĩ sâu.
- Hiệu năng so sánh: Trong các bài test của CodeRabbit, Opus 4.7 ở mức nỗ lực cao cho tốc độ xử lý nhanh hơn đáng kể so với GPT-5.4 xhigh trên cùng một harness (khung chạy thử nghiệm).
Còn thay đổi gì khác so với Opus 4.6?
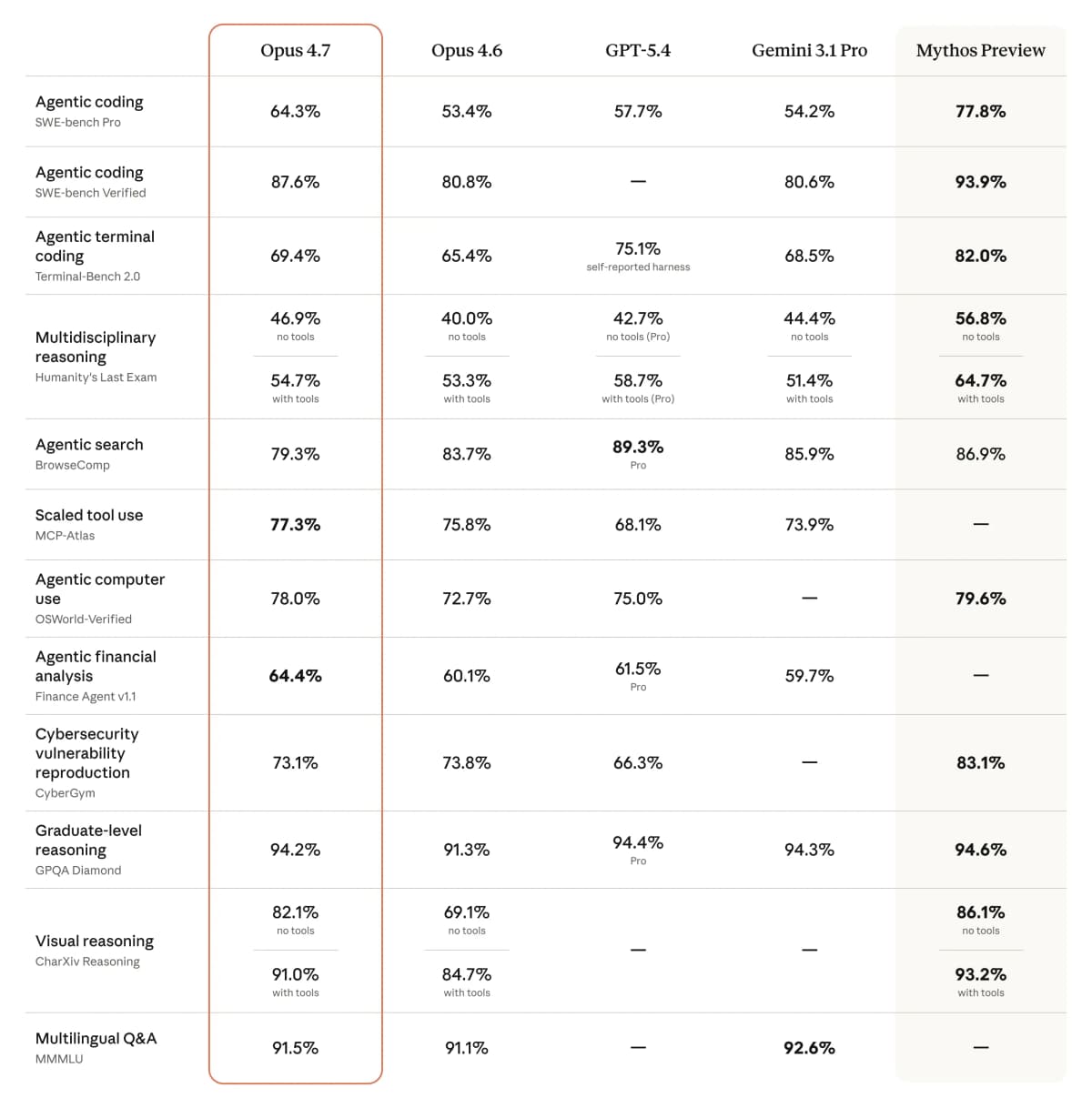
Khả năng lập trình và điểm chuẩn
Opus 4.7 đạt mức tăng 13% trên bộ benchmark 93 tác vụ nội bộ. Trên SWE-bench Pro, model chứng minh năng lực vượt trội trong việc xử lý các lỗi logic mà phiên bản 4.6 thường bỏ qua. Đặc biệt, model đạt trạng thái state-of-the-art trên GDPval-AA, một thước đo quan trọng về giá trị kinh tế của AI trong công việc chuyên môn.
Thị giác máy tính độ phân giải cao
Hỗ trợ độ phân giải lên đến 2,576 pixels (~3.75 megapixels) trên cạnh dài nhất, tăng gấp 3 lần. Điều này cho phép các tác nhân (agents) đọc được các văn bản cực nhỏ trong tài liệu pháp lý hoặc các linh kiện chi tiết trên sơ đồ mạch điện.
Task Budgets (Beta)
Tính năng này cho phép lập trình viên đặt giới hạn chi tiêu token cho một tác vụ cụ thể. Đây là công cụ quản trị rủi ro tài chính thiết yếu cho các hệ thống chạy tự chủ trong thời gian dài.
Tokenizer mới và rủi ro "Literalness"
Opus 4.7 sử dụng tokenizer mới giúp tuân thủ chỉ dẫn chặt chẽ hơn (literal instruction following). Tuy nhiên, đây là một "con dao hai lưỡi": model sẽ thực hiện chính xác những gì được viết thay vì tự suy diễn ý định của người dùng như bản 4.6. Lập trình viên bắt buộc phải tinh chỉnh lại prompt (re-tune prompts) để tránh việc model thực hiện sai lệch do hiểu quá sát nghĩa đen.
Lập trình viên cần xử lý những thay đổi API gây lỗi nào?
Để tránh lỗi 400 (Bad Request) khi nâng cấp hệ thống, các kỹ sư cần thực hiện các điều chỉnh kỹ thuật sau:
- Xóa bỏ tham số lấy mẫu:
temperature,top_p, vàtop_kkhông còn được hỗ trợ. Nếu cấu hình các giá trị này khác mặc định, API sẽ trả về lỗi 400 ngay lập tức. Mọi sự điều chỉnh tính sáng tạo/logic giờ đây phải thông qua tham sốeffort. - Loại bỏ budget_tokens: Trong cấu hình
thinking, thuộc tính này đã bị thay thế bởi cơ chếadaptive. - Triển khai
stop_details: Model hiện cung cấp thông tin chi tiết về lý do từ chối (refusal). Lập trình viên nên tận dụng dữ liệu này để xây dựng logic điều hướng người dùng thay vì chỉ hiển thị thông báo lỗi chung chung. - Quản lý hiển thị suy nghĩ: Nội dung suy luận bị ẩn mặc định. Nếu cần truy xuất để audit, phải cấu hình lại trong yêu cầu API.
- Lưu ý về dung lượng token: Tokenizer mới có thể làm tăng số lượng token từ 1.0 đến 1.35 lần cho cùng một nội dung đầu vào, ảnh hưởng trực tiếp đến hạn ngạch chi phí.
Khi nào Opus 4.7 không phải lựa chọn đúng?
- So với Claude Mythos Preview: Opus 4.7 vẫn đứng sau Mythos về khả năng căn chỉnh an toàn (alignment) và trí tuệ tổng quát. Nếu ưu tiên hàng đầu là độ an toàn tuyệt đối, Mythos là lựa chọn tốt hơn.
- Hạn chế an ninh mạng: Dưới chiến lược Project Glasswing, Opus 4.7 được trang bị các rào cản tự động để chặn các yêu cầu rủi ro cao. Các chuyên gia bảo mật cần đăng ký Cyber Verification Program để vượt qua các hạn chế này cho mục đích nghiên cứu hợp pháp.
- Vấn đề hiệu năng thực tế: Mặc dù mạnh mẽ, Opus 4.7 vẫn gặp một số báo cáo về lỗi gọi công cụ (tool-calling errors) và độ dài phản hồi quá mức (verbosity). Ngoài ra, chi phí thực tế có thể cao hơn 4.6 do cơ chế suy nghĩ sâu tiêu tốn nhiều token hơn.
Điều này có ý nghĩa gì trong thực tế — với lập trình viên, người dùng chat, và tất cả mọi người?
Sự ra đời của Opus 4.7 chuyển dịch trọng tâm từ AI hỗ trợ sang AI tự chủ hoàn toàn trong các quy trình dài hơi.
- Với lập trình viên: Khả năng "loop resistance" (chống lặp vô hạn) và "graceful error recovery" (phục hồi lỗi linh hoạt) cho phép model làm việc liên tục hàng giờ. Ví dụ điển hình là việc Opus 4.7 tự xây dựng engine text-to-speech bằng Rust, bao gồm cả các kernel SIMD và tự viết test để xác minh đầu ra mà không cần giám sát.
- Với doanh nghiệp: Sự chính xác trong trích dẫn (citation precision) của các đối tác như Harvey hay Hebbia cho thấy AI đã có thể xử lý các nhiệm vụ pháp lý phức tạp như phân biệt điều khoản "assignment" và "change-of-control" với độ tin cậy cao.
- Với hệ thống tác nhân: Các nền tảng như Devin hay Cursor tận dụng khả năng hoạt động xuyên suốt (long-horizon autonomy) để giải quyết các dự án lớn, nơi model phải tự duy trì ngữ cảnh và mục tiêu cuối cùng qua hàng nghìn dòng lệnh.