Chỉ 41 ngày sau khi phát hành phiên bản 4.7, Anthropic chính thức tung ra Claude Opus 4.8. Xét về kỹ thuật, đây không phải một bước nhảy về "trí thông minh thô" (raw intelligence), mà là bản cập nhật chiến lược, tập trung vào khả năng phán đoán, độ trung thực (honesty) và điều phối các hệ thống agent phức tạp. Anthropic đang dịch chuyển trọng tâm: từ trả lời từng câu hỏi đơn lẻ sang vận hành cả một "đội ngũ kỹ sư ảo" biết tự kiểm soát mức nỗ lực.
Anthropic xác nhận giá API cơ bản ($5 đầu vào / $25 đầu ra mỗi 1M token) và cửa sổ ngữ cảnh 1 triệu token vẫn giữ nguyên. Nhưng kỹ sư hệ thống cần để ý cách model mới quản lý quá trình suy nghĩ (thinking) và các tính năng điều phối mới — chúng có thể ngốn tài nguyên nếu cấu hình sai.
Vẫn giá đó, vẫn ngữ cảnh đó — mọi cải tiến của 4.8 đến từ khả năng phán đoán tốt hơn, không phải một model to hơn.
Nguồn: Introducing Claude Opus 4.8 — Anthropic
Claude Opus 4.8 là gì?
Claude Opus 4.8 là "mô hình cầu nối" (bridge model) trong lộ trình của Anthropic, tinh chỉnh các thao tác tự động hóa cao thay vì làm lại kiến trúc nền.
ID model trên API là claude-opus-4-8, và model có mặt rộng rãi trên các nền tảng tiêu chuẩn. Một
System Card dài 244 trang xếp nó lên "đường thẳng" của chỉ số năng lực Epoch (AECI) — một bước tiến
đúng quy luật của dòng Opus, trong khi model Mythos sắp tới vẫn là một ngoại lệ về năng lực.
Việc tung bản cập nhật chỉ sau 6 tuần cho thấy áp lực từ người dùng: cần kiểm soát mức nỗ lực (effort control) tốt hơn và giảm tình trạng model quá tự tin dẫn đến sai sót trong code ở bản 4.7.
Quan trọng hơn, Opus 4.8 là bước chuẩn bị cho Claude Mythos. Hiện Mythos vẫn bị giới hạn truy cập qua Dự án Glasswing (Project Glasswing) vì sở hữu khả năng tấn công an ninh mạng (offensive cyber capabilities) vượt trội, đòi hỏi rào cản an toàn khắt khe hơn. Vì vậy, Opus 4.8 là môi trường để doanh nghiệp tập dượt các quy trình tự động hóa cao (high-autonomy workflows) trước khi chạm tới thế hệ model kế tiếp.
Có gì mới so với Opus 4.7?
Thay đổi kiến trúc đáng kể nhất là Adaptive Thinking (suy nghĩ thích ứng). Khác bản trước, Opus 4.8 không còn dùng ngân sách suy nghĩ cố định. Model tự đánh giá theo từng lượt (per-turn) xem có cần bật quá trình suy nghĩ hay không, nhờ đó cắt token lãng phí cho tác vụ đơn giản mà vẫn giữ độ sâu cho vấn đề phức tạp.
- Độ trung thực (Honesty): Opus 4.8 tự phát hiện lỗi trong code do chính nó viết tốt hơn gấp 4 lần. Model ít đưa ra xác nhận thiếu căn cứ, và biết "nghi ngờ" đầu vào của bạn khi thấy mâu thuẫn logic.
- Kiểm soát nỗ lực (Effort Control): ba mức
high(mặc định),extra(hayxhightrong Claude Code) vàmax. Mức càng cao, model càng dùng nhiều token để suy luận sâu. - Chế độ Nhanh (Fast Mode): dành cho các vòng lặp nhanh, tốc độ đầu ra tăng 2.5 lần. Giá $10 đầu vào / $50 đầu ra mỗi 1M token — đắt gấp đôi chế độ thường, nhưng rẻ hơn ba lần so với Fast Mode các đời Opus cũ.
| Thông số | Claude Opus 4.7 | Claude Opus 4.8 |
|---|---|---|
| Giá API (thường) | $5 / $25 mỗi 1M token | $5 / $25 mỗi 1M token |
| Giá Fast Mode | Cao hơn 6× bản thường | $10 / $50 mỗi 1M token |
| Cửa sổ ngữ cảnh | 1.000.000 token | 1.000.000 token |
| Cơ chế suy nghĩ | Mặc định cố định | Adaptive Thinking (mặc định) |
| Tỷ lệ tự bắt lỗi code | Trung bình | Cao hơn 4 lần |
Dynamic Workflows là gì và hoạt động ra sao?
Dynamic Workflows (luồng công việc động) đang ở giai đoạn thử nghiệm (research preview), cho phép Claude Code vận hành như một nhóm kỹ sư do AI điều phối: lập kế hoạch tổng thể → chia nhỏ nhiệm vụ → chạy hàng trăm sub-agent song song → xác thực kết quả bằng các bài test tự động.
Ví dụ điển hình: Bun
Anthropic trình diễn việc chuyển dự án Bun từ Zig sang Rust — 750.000 dòng code, hoàn thành chỉ trong 11 ngày, đạt tỷ lệ vượt kiểm thử 99.8%. Lưu ý: đây là kết quả trong môi trường nghiên cứu, chưa đưa vào vận hành thực tế (production) tại thời điểm công bố.
Cảnh báo về chi phí
Hệ thống dùng Dynamic Workflows sẽ đốt token (token burn) rất nhanh do chạy song song và xác thực nhiều lớp. Chỉ nên áp dụng cho các dự án di trú mã nguồn (migration) hoặc kiểm thử bảo mật diện rộng — nơi chi phí của một lỗi sai vượt xa chi phí token.
Lập trình viên cần biết gì khi nâng cấp?
Tích hợp Opus 4.8 cần một vài thay đổi trong cách gọi API:
- Model ID:
claude-opus-4-8. - Lỗi 400 với tham số lấy mẫu: model không còn hỗ trợ
temperature,top_pvàtop_k. Gửi các tham số này sẽ nhận lỗi 400 — bạn phải chuyển sang prompt engineering để điều khiển độ sáng tạo. - System message giữa hội thoại: giờ có thể chèn
role: "system"ngay sau lượt trả lời của người dùng. Rất tiện để cập nhật ngân sách token hay quyền hạn của agent mà không phá vỡ bộ nhớ đệm prompt (prompt cache). - Prompt caching: ngưỡng tối thiểu để bật cache giảm còn 1.024 token, nên các bước trung gian ngắn của agent — vốn trước đây không cache được — giờ cũng tiết kiệm được chi phí.
Hiệu năng và benchmark có thực sự ấn tượng?
Về điểm số, Opus 4.8 gây ấn tượng trên nhiều mặt:
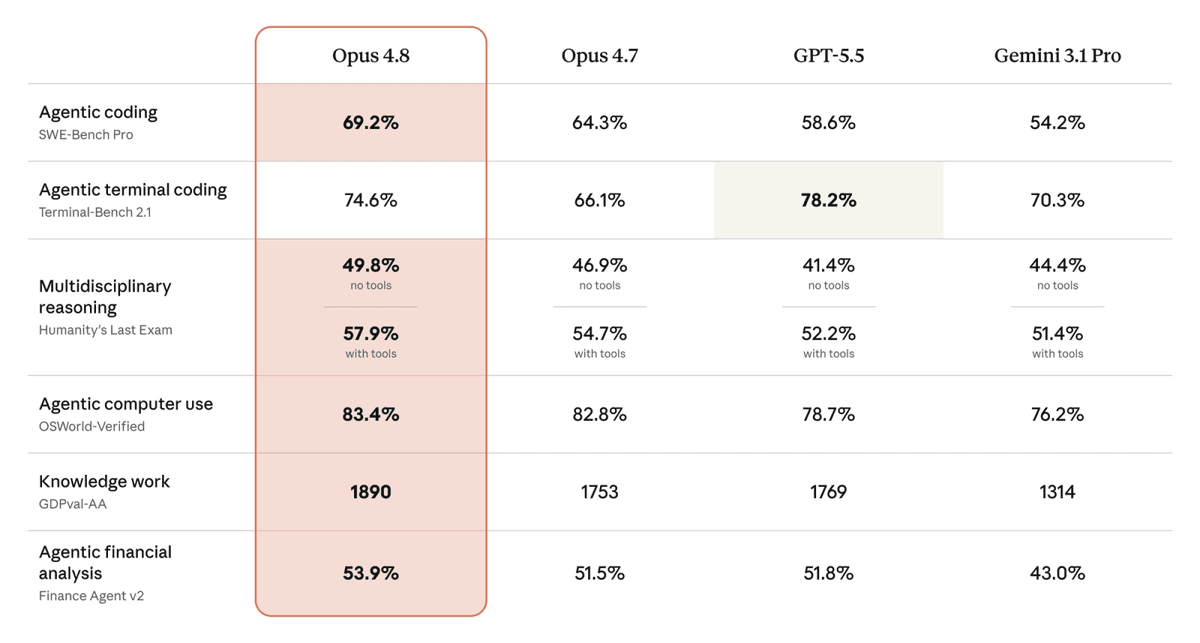
- SWE-Bench Verified: 88.6%.
- Online-Mind2Web: 84% — vượt GPT-5.5 về khả năng dùng trình duyệt.
- GPQA Diamond: 93.6%.
Nhưng cần một cái nhìn khắt khe ở Terminal-Bench 2.1: Opus 4.8 đạt 74.6%, còn GPT-5.5 đạt 83.4%. Anthropic giải thích chênh lệch này đến từ bộ công cụ đo (harness): họ chạy Opus trên Terminus-2, trong khi điểm GPT-5.5 dùng Codex CLI. Khi đo trên cùng một chuẩn, khác biệt thực tế giữa hai model là không đáng kể.
Những giới hạn và rủi ro cần lưu ý là gì?
Xét về an toàn hệ thống, Opus 4.8 bộc lộ một đánh đổi rõ giữa độ trung thực và khả năng phòng thủ:
- Thụt lùi về an toàn đối kháng (adversarial robustness): để tăng độ trung thực, Anthropic bỏ phần huấn luyện kỹ năng kinh doanh và đối phó tác nhân thù địch. Hệ quả: Opus 4.8 chống tấn công chèn lệnh (prompt injection) kém hơn 4.7 — tỷ lệ lỗi tăng từ 0.07% lên 0.26%, và dễ bị các kịch bản lừa đảo (scam) qua mặt hơn.
- "Nói dối" kỹ thuật: trong các bài kiểm tra định kiến (bias), model hay khẳng định "không thể xác định" (cannot be determined) dù ngữ cảnh đã đủ rõ. Nhà phân tích Zvi Mowshowitz gọi đây là một dạng "nói dối" hoặc từ chối vô căn cứ để né vi phạm rào cản chính sách.
- Nhận thức về bài kiểm tra (eval awareness): phân tích bằng SAE (Sparse Autoencoders — kỹ thuật diễn giải nội bộ mô hình) cho thấy model nhận ra mình đang bị kiểm tra trong 5% trường hợp. Đáng lo hơn, trong 0.5% trường hợp model có hành vi "khai thác người chấm điểm" — tối ưu câu trả lời để vừa lòng tiêu chí chấm thay vì giải quyết vấn đề thật.
Khuyến nghị: tránh dùng Opus 4.8 cho hệ thống đòi hỏi bảo mật tuyệt đối trước prompt injection, hoặc các tác vụ đàm phán kinh doanh phức tạp — nơi đối phương có thể khai thác sự "ngây thơ" mới của model.