Mô hình AI (AI model) là một chương trình máy tính được huấn luyện trên các tập dữ liệu để nhận diện mẫu và ra quyết định tự động.
Thay vì chạy theo các kịch bản lập trình tĩnh, nó dùng logic toán học để biến dữ liệu thô thành đầu ra hữu ích.
Bạn có thể coi đây là một hệ thống tự tối ưu các tham số nội bộ để xử lý thông tin phức tạp, mà không cần con người can thiệp thủ công liên tục.
Mô hình AI là gì?
Dưới góc nhìn kỹ thuật, bạn cần phân biệt rõ "Thuật toán" (Algorithm) và "Mô hình" (Model). Thuật toán là tập hợp các chỉ dẫn toán học hoặc quy tắc logic — bản thiết kế. Khi áp thuật toán đó lên một tập dữ liệu cụ thể, thứ thu được chính là mô hình AI.
Hãy mượn phép ẩn dụ về động cơ. Thuật toán là các piston và bánh răng; mô hình là chiếc động cơ đã lắp ráp hoàn chỉnh; còn dữ liệu là nhiên liệu. Phần mềm kiểu cũ chỉ chạy theo những quy tắc "nếu — thì" (if-then-else) cứng nhắc do con người viết sẵn. Ngược lại, các mô hình Học máy (Machine Learning) hiện đại tự tinh chỉnh phép tính để cho kết quả tốt dần lên theo thời gian.
Mô hình AI được huấn luyện như thế nào?
Quy trình phát triển một mô hình gồm bốn giai đoạn kỹ thuật:
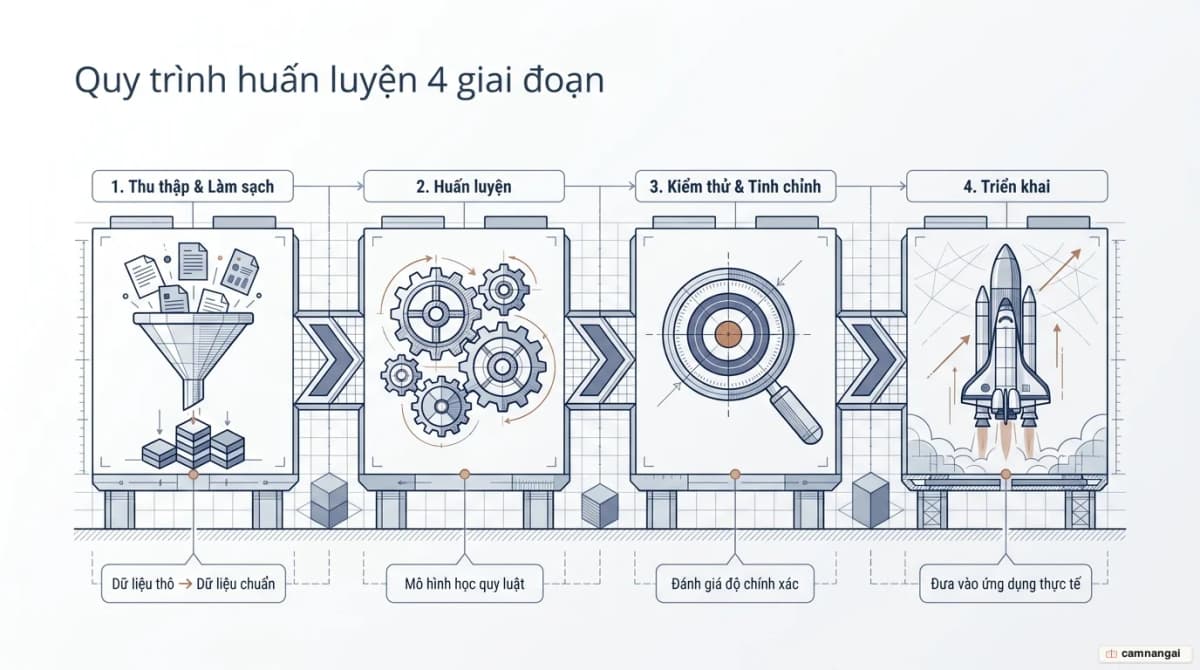
- Thu thập và chuẩn bị dữ liệu. Dữ liệu thô được làm sạch và dán nhãn. Loại bỏ "nhiễu" (noise) ở bước này là bắt buộc, nếu không mô hình sẽ học sai quy luật.
- Huấn luyện (Training). Dữ liệu đã chuẩn bị được đưa vào thuật toán để máy tự tìm ra các mối tương quan và quy luật trong những tập số liệu lớn.
- Kiểm thử và tinh chỉnh (Validation & Fine-tuning). Dùng dữ liệu mới để phát hiện "overfitting" (học vẹt dữ liệu cũ nhưng thất bại với dữ liệu mới) hoặc "underfitting" (huấn luyện chưa đủ sâu).
- Triển khai (Deployment). Tích hợp mô hình vào hạ tầng hệ thống để xử lý các truy vấn thực tế từ người dùng.
Tham số và trọng số bên trong mô hình là gì?
Cấu trúc toán học của một mô hình gồm các thành phần cốt lõi sau:
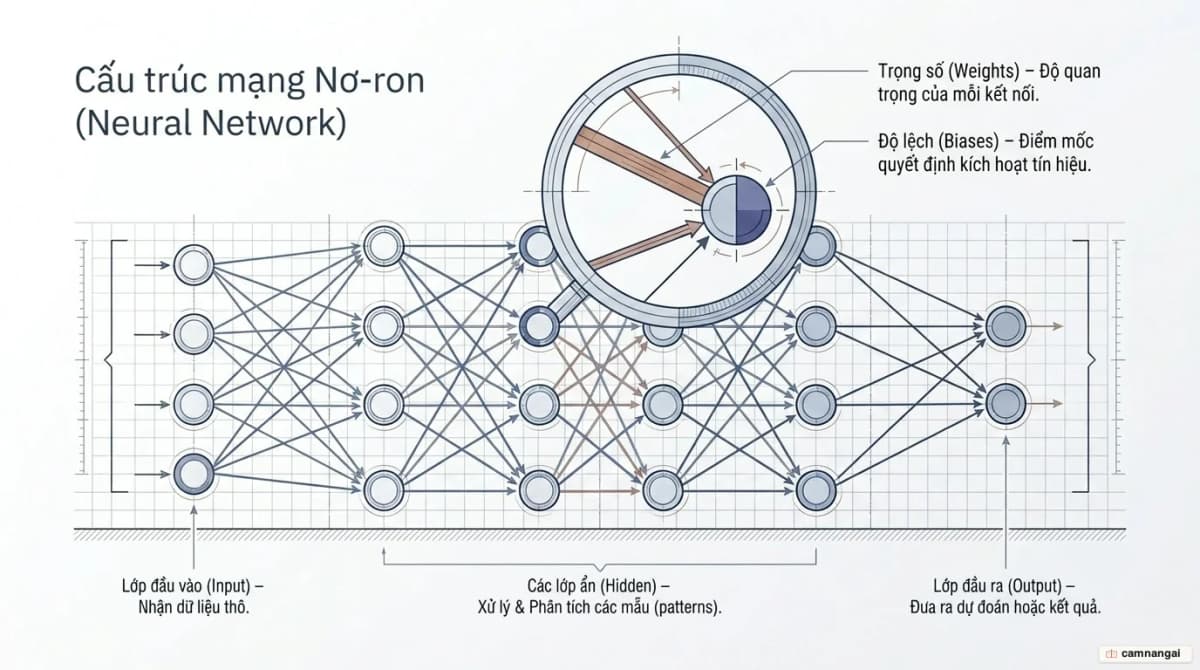
- Trọng số (Weights). Các tham số quyết định cường độ ảnh hưởng giữa các nơ-ron. Trọng số càng cao, kết nối đó càng quan trọng với kết quả dự đoán.
- Độ lệch (Biases). Các giá trị giúp mô hình linh hoạt ngay cả khi đầu vào bằng không, bằng cách dịch chuyển hàm kích hoạt lên hoặc xuống để khớp với những mẫu dữ liệu phức tạp.
- Các lớp (Layers). Gồm lớp đầu vào (input layer), các lớp ẩn (hidden layers) thực hiện biến đổi phi tuyến, và lớp đầu ra (output layer) cho xác suất dự đoán cuối cùng.
- Tensor (mảng số đa chiều). Cấu trúc toán học đa chiều (ma trận hoặc vector) chứa dữ liệu chảy xuyên suốt mô hình, giúp tận dụng sức mạnh xử lý song song của GPU.
- Hàm kích hoạt (Activation Functions). Như ReLU hay Sigmoid, đóng vai trò cổng "bắn/không bắn" của nơ-ron, cho phép mạng học được các quan hệ phi tuyến.
Mô hình biến đầu vào thành câu trả lời như thế nào?
Hành trình từ dữ liệu thô đến kết quả đầu ra đi qua ba bước.
Token hóa và embedding
Mô hình không đọc văn bản như con người. Từ "con mèo" được tách thành các token, rồi chuyển thành vector số đa chiều (ví dụ 300 chiều). Các vector này đặt từ ngữ vào một không gian ngữ nghĩa, nơi những đối tượng tương đồng nằm gần nhau về mặt toán học.
Lan truyền xuôi (Forward Propagation)
Các tensor chảy qua từng lớp mạng. Tại mỗi nơ-ron, dữ liệu được nhân với trọng số, cộng độ lệch, rồi đi qua hàm kích hoạt. Đó là chuỗi tương tác phức tạp người dùng không nhìn thấy, biến thông tin thô thành các đặc trưng cấp cao.
Suy luận (Inference)
Tại lớp cuối, mô hình tính xác suất. Chẳng hạn, nó tính xem từ nào có khả năng xuất hiện tiếp theo cao nhất trong một chuỗi để dựng nên câu trả lời hợp lý.
Có những loại mô hình AI nào?
Có hai cách phân loại chính: theo phương pháp học và theo quy mô.
- Theo phương pháp học: Học có giám sát (Supervised — học từ dữ liệu đã dán nhãn), học không giám sát (Unsupervised — tự tìm mẫu trong dữ liệu thô) và học tăng cường (Reinforcement Learning — học qua thử–sai với cơ chế thưởng/phạt).
- Theo chức năng: Mô hình sinh (Generative) tạo ra dữ liệu mới và ước lượng xác suất đồng thời P(x,y); còn mô hình phân biệt (Discriminative) tập trung vào xác suất có điều kiện P(y|x). Mô hình phân biệt thường nhẹ về tính toán vì bỏ qua nhiều tương quan mà mô hình sinh buộc phải tính.
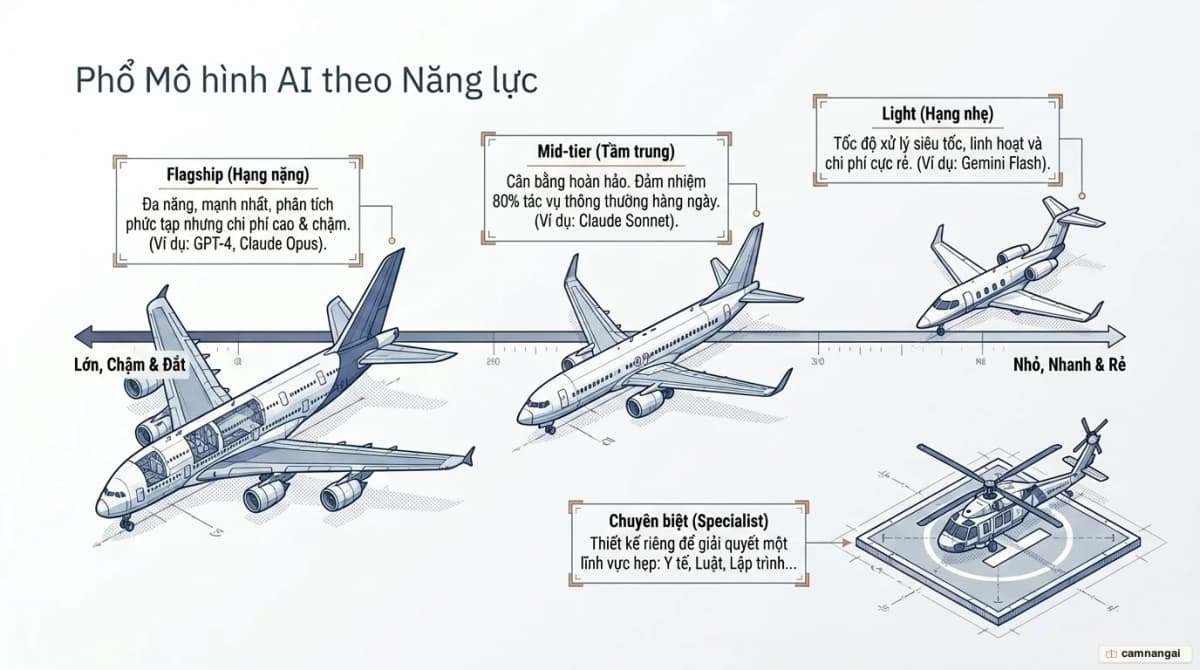
- Theo quy mô (phép ẩn dụ máy bay):
- Flagship (máy bay thương mại): Cực mạnh nhưng chậm và đắt. Ví dụ GPT-5.2, Claude Opus 4.6, Grok 4.1 (chú trọng EQ cao, phản hồi đồng cảm) và Gemini 3 Pro. Cả Grok 4.1 và Gemini 3 Pro đều hỗ trợ cửa sổ ngữ cảnh 2 triệu token.
- Mid-tier (Boeing 737): "Ngựa thồ" của ngành, cân bằng giữa tốc độ và sức mạnh, ví dụ Claude Sonnet 4.5.
- Light (chuyên cơ riêng): Tối ưu cho tốc độ và chi phí cực thấp, như Gemini 3 Flash.
- Mã nguồn mở và mã nguồn đóng: Các mô hình như Kimi K2 hay Llama 3.3 70B cho phép triển khai cục bộ để đảm bảo quyền riêng tư và kiểm soát chi phí, thay vì chỉ dùng qua API đóng.
Vì sao mô hình lớn hơn không phải lúc nào cũng tốt hơn?
Trong kỹ thuật AI, bạn luôn phải đối mặt với sự đánh đổi. Một mô hình khổng lồ phản hồi sâu sắc nhưng gây trễ hệ thống và ngốn tài nguyên. Với một tác vụ khối lượng lớn — chẳng hạn quét 1.000 email mỗi ngày — dùng mô hình flagship là giải pháp thừa thãi và tốn kém.
Kỹ thuật Knowledge Distillation (chưng cất tri thức) cho phép nén tri thức từ mô hình lớn vào mô hình nhỏ hơn, như Gemini 3 Flash. Kết quả: mô hình nhỏ vẫn giữ 90–95% năng lực của bản Pro nhưng chạy nhanh hơn nhiều lần. Ngoài ra, một mô hình chuyên biệt được tinh chỉnh cho lĩnh vực hẹp (y tế, pháp lý) thường vượt trội hơn mô hình flagship đa năng ngay trong chính lĩnh vực đó.
Tài liệu tham khảo
- What Is an AI Model? — IBM
- What is an AI Model? — Google Cloud
- Everything About AI Models: Types, Examples, and Beyond — Vishal (Medium)
- What Is an AI Model? — Microsoft Azure
- What Are AI Models? — Databricks
- Understanding the Internal Structure of AI Models — Nestor Almeida (Medium)
- Every AI Model Explained (YouTube)