Cửa sổ ngữ cảnh (context window) là bộ nhớ làm việc (working memory) giới hạn lượng dữ liệu mà một mô hình ngôn ngữ lớn (LLM) có thể xử lý và tham chiếu tại một thời điểm. Nó lưu toàn bộ chỉ dẫn, lịch sử hội thoại và dữ liệu đính kèm để mô hình "nhìn thấy" khi tạo phản hồi. Hiểu đơn giản, vượt quá giới hạn này thì mô hình bắt đầu quên các thông tin cũ. Với tư cách kỹ sư, bạn cần coi đây là một tài nguyên hệ thống hữu hạn cần tối ưu, chứ không phải một không gian lưu trữ vô biên.
Hiểu rõ cơ chế vận hành của context window giúp bạn xây dựng ứng dụng AI ổn định, giảm chi phí API và tránh các lỗi logic do suy giảm khả năng truy xuất thông tin (recall) trong những chuỗi hội thoại phức tạp.

Cửa sổ ngữ cảnh là gì?
Cửa sổ ngữ cảnh là "bộ nhớ tạm thời" của mô hình trong quá trình suy luận (inference), phân biệt hoàn toàn với dữ liệu huấn luyện (training data)
— vốn là kho tri thức tĩnh đã học từ trước.
Token: đơn vị cơ bản
Dung lượng của context window được đo bằng token. Đây là đơn vị ngôn ngữ nhỏ nhất mà LLM xử lý, có thể là một ký tự, một phần của từ hoặc cả một từ.
- Số liệu cụ thể: Một từ tiếng Anh trung bình tương đương khoảng 1,5 token. Như vậy, 100 từ chiếm khoảng 150 token.
- Ví dụ phân tách: Từ "amoral" có thể được tokenizer tách thành hai token: "a" (tiền tố làm thay đổi ý nghĩa) và "moral". Ngược lại, từ "cat" thường chỉ là một token duy nhất vì không thể chia nhỏ hơn về mặt ngữ nghĩa.
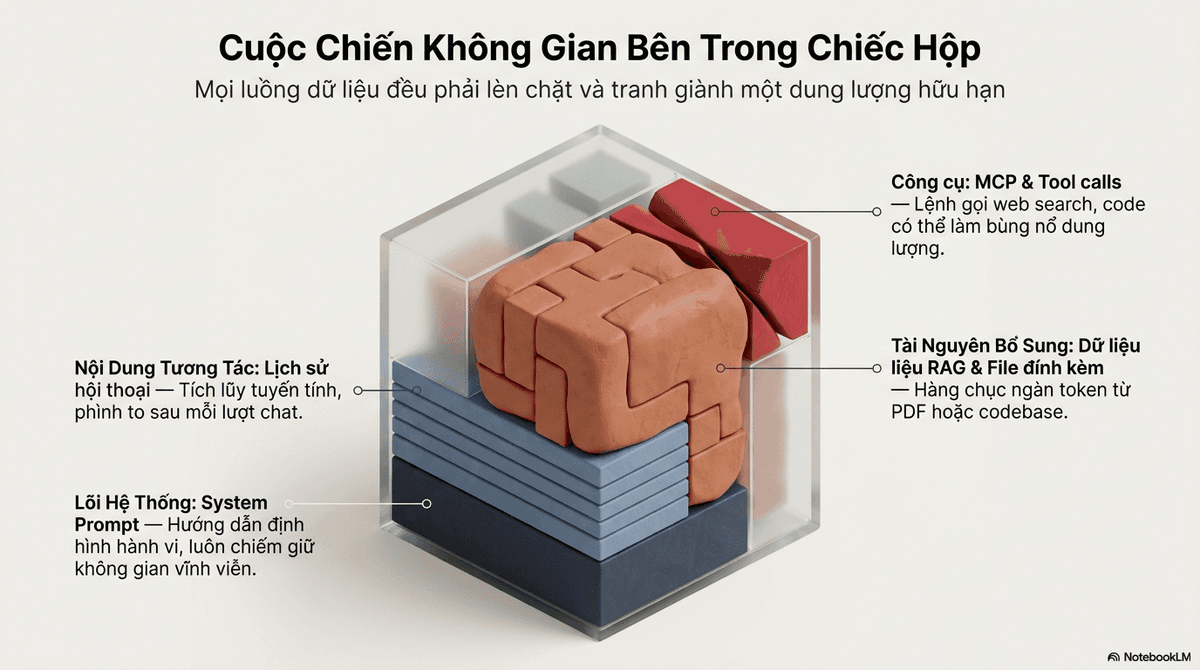
Các thành phần chiếm dụng bộ nhớ
Mọi dữ liệu nằm trong vòng đời của một yêu cầu đều tiêu tốn dung lượng, bao gồm:
- System prompt: Các chỉ dẫn cấu hình hành vi.
- Lịch sử hội thoại: Tin nhắn của người dùng và phản hồi trước đó của trợ lý.
- Tài liệu đính kèm: Mã nguồn, tệp PDF, hình ảnh.
- Dữ liệu từ RAG (Retrieval-Augmented Generation): Các đoạn văn bản (chunks) được truy xuất từ vector database.
Cửa sổ ngữ cảnh hoạt động như thế nào?
Cơ chế tự chú ý (self-attention)
Các mô hình Transformer dùng cơ chế self-attention để tính trọng số mối quan hệ giữa các token. Cơ chế này cho phép mô hình hiểu được sự liên quan giữa các thực thể nằm cách xa nhau trong văn bản. Tuy nhiên, kích thước context window giới hạn phạm vi mà cơ chế này có thể "quét" qua cùng lúc.
Chu trình input-output
Mỗi tương tác API là một trạng thái mới (stateless). Để duy trì hội thoại, bạn phải gửi lại toàn bộ lịch sử:
- Giai đoạn Input: Chứa toàn bộ lịch sử trước đó cùng tin nhắn hiện tại.
- Giai đoạn Output: Phản hồi mới được tạo ra và sẽ cộng dồn vào Input của lượt tiếp theo. Quá trình này khiến số lượng token tăng trưởng tuyến tính, dần lấp đầy "hộp chứa" bộ nhớ.
Đặc thù trên các dòng mô hình Claude
- Quy mô bộ nhớ: Các model như Claude Opus 4.8 và Mythos Preview hiện hỗ trợ context window lên tới 1 triệu token. Các dòng Sonnet 4.5/4 thường giới hạn ở 200k.
- Xử lý tệp tin: Cho phép đính kèm tới 600 hình ảnh hoặc trang PDF (giảm xuống 100 với các model có context window 200k).
- Extended Thinking (tư duy mở rộng): Các khối tư duy (thinking blocks) được tính vào giới hạn token của lượt hiện tại. API tự động lược bỏ chúng ở các lượt sau để tiết kiệm dung lượng.
- Lưu ý về Tool Use: Khi dùng công cụ kết hợp với extended thinking, bạn bắt buộc phải gửi lại khối tư duy nguyên vẹn (kèm chữ ký số) cùng kết quả công cụ. Nếu tự ý lược bỏ hoặc chỉnh sửa khối tư duy trong chu trình này, API sẽ trả về lỗi xác thực.
Vì sao nhiều ngữ cảnh hơn không phải lúc nào cũng tốt hơn?
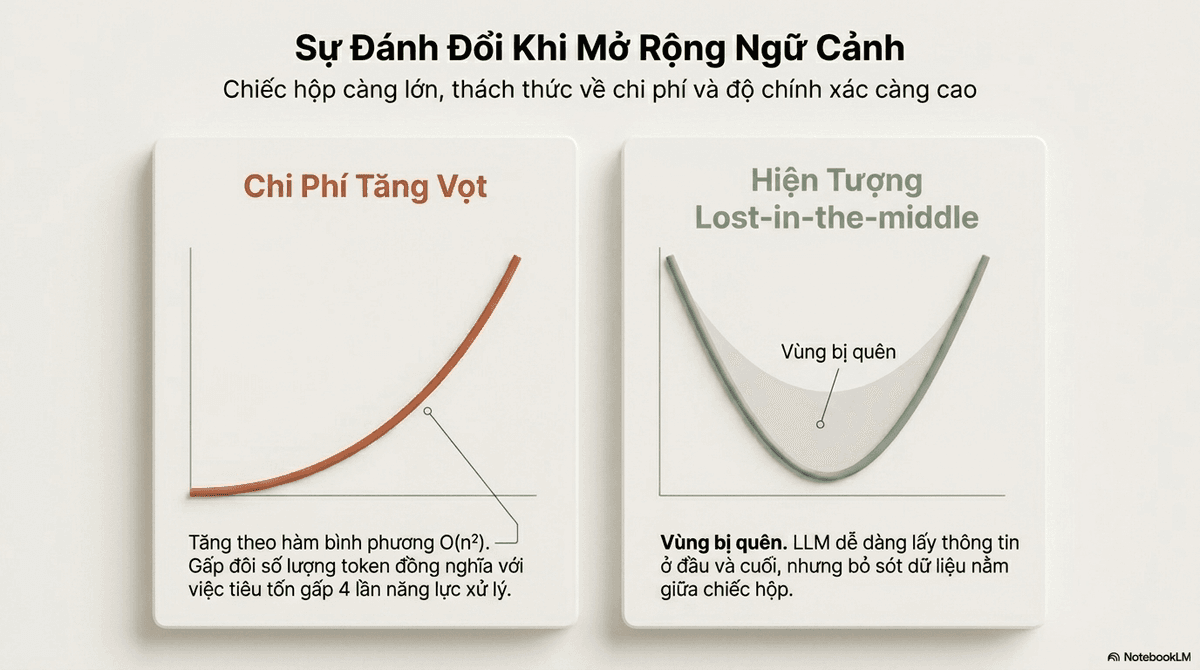
- Chi phí tính toán O(n^2): Tài nguyên xử lý tăng theo hàm bình phương so với độ dài chuỗi. Gấp đôi lượng token đầu vào tiêu tốn gấp bốn lần sức mạnh tính toán, dẫn đến độ trễ (latency) rất cao.
- Hiện tượng "lost-in-the-middle": LLM thường ưu tiên thông tin ở đầu (primacy bias) và cuối (recency bias) của prompt. Khi thông tin quan trọng nằm giữa một khối văn bản khổng lồ, mô hình dễ gặp "context rot" và bỏ sót chi tiết.
- Rủi ro an toàn: Context window lớn làm tăng bề mặt tấn công. Kẻ tấn công có thể giấu các câu lệnh đối nghịch (adversarial prompts) sâu trong tài liệu dài để thực hiện kỹ thuật jailbreaking (vượt qua các rào chắn an toàn của mô hình).
Điều gì xảy ra khi vượt quá giới hạn cửa sổ ngữ cảnh?
Khi chạm giới hạn, mô hình mất khả năng tham chiếu các thông tin cũ nhất. Điều này dẫn đến:
- Ảo giác (hallucinations): Mô hình tự bịa thông tin để duy trì tính logic của câu trả lời do thiếu dữ liệu thực tế.
- Mất nhất quán: Mô hình quên các ràng buộc trong system prompt hoặc các thỏa thuận ở đầu phiên chat.
Phản hồi từ API:
- Các model cũ: Trả về lỗi 400 (validation error).
- Các model mới (Claude 4.5+): Chấp nhận yêu cầu nhưng cắt ngang phản hồi ngay khi chạm ngưỡng, kèm mã
stop_reason: "model_context_window_exceeded".
Làm thế nào để quản lý cửa sổ ngữ cảnh hiệu quả?
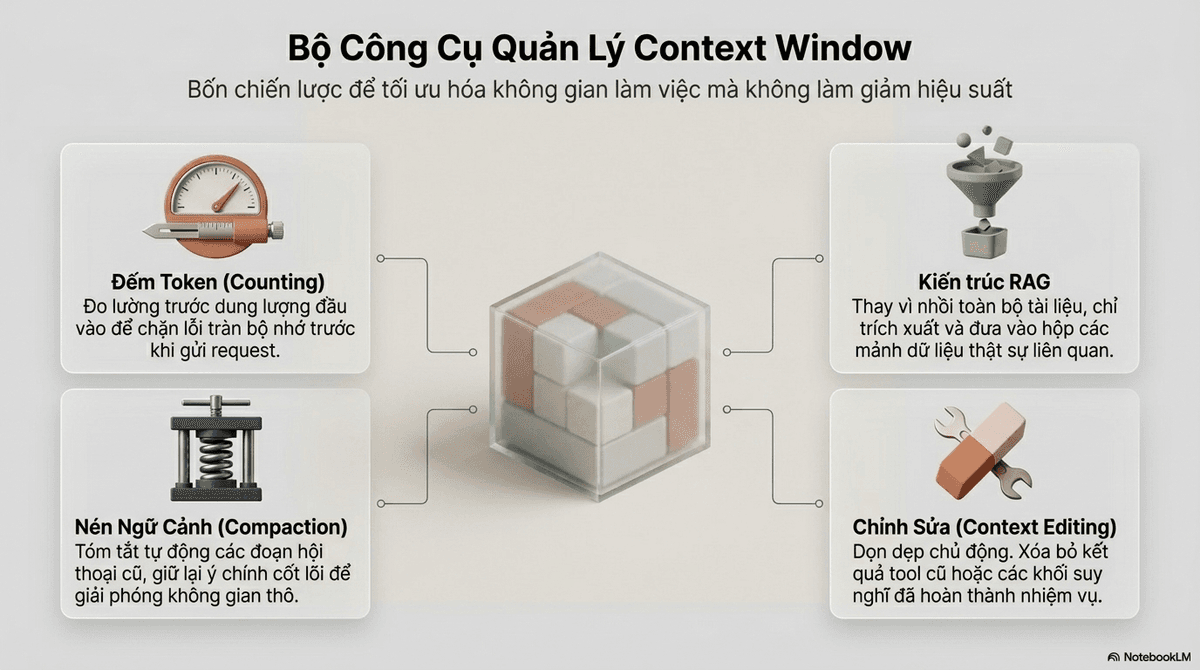
- Token counting: Luôn dùng API đếm token để kiểm soát "ngân sách" trước khi gửi request.
- Context awareness: Các model Claude mới (4.5/4.6) có khả năng tự theo dõi ngân sách token còn lại. Thiếu tính năng này, mô hình giống như thí sinh trong show nấu ăn mà không có đồng hồ. Nhờ context awareness, mô hình điều chỉnh chiến lược suy luận để hoàn thành tác vụ trong phạm vi dung lượng cho phép.
- Compaction (nén ngữ cảnh): Dùng server-side summarization (có trên Claude Opus 4.8, Sonnet 4.6...) để tóm tắt các hội thoại cũ, giữ lại ý chính thay vì lưu toàn văn.
- Context editing: Chủ động xóa kết quả công cụ cũ (tool result clearing) hoặc xóa khối tư duy sau khi kết thúc chu trình gọi công cụ.
- RAG (Retrieval-Augmented Generation): Thay vì nạp toàn bộ 1000 trang tài liệu, hãy dùng vector search để chỉ lấy ra 3–5 đoạn liên quan nhất.
- Thực hành tốt: Thường xuyên chạy lệnh
/clearđể làm mới bộ nhớ của agent khi chuyển sang chủ đề mới, tránh tích tụ thông tin thừa giữa các phiên.