Context engineering is the systems discipline of designing and managing the information ecosystem that determines what a model knows at inference time.
While prompt engineering focuses on the instruction layer, context engineering manages the full information state — system instructions, tools, message history, and external data. You must treat the context window as a finite resource that requires active curation to keep a model reliable.
Think of the LLM as a CPU and the context window as RAM. Just as an operating system manages what is loaded into RAM to prevent performance degradation, you use context engineering to orchestrate exactly what the model sees for each specific step of a task. This keeps the model operating with the highest signal-to-noise ratio possible.
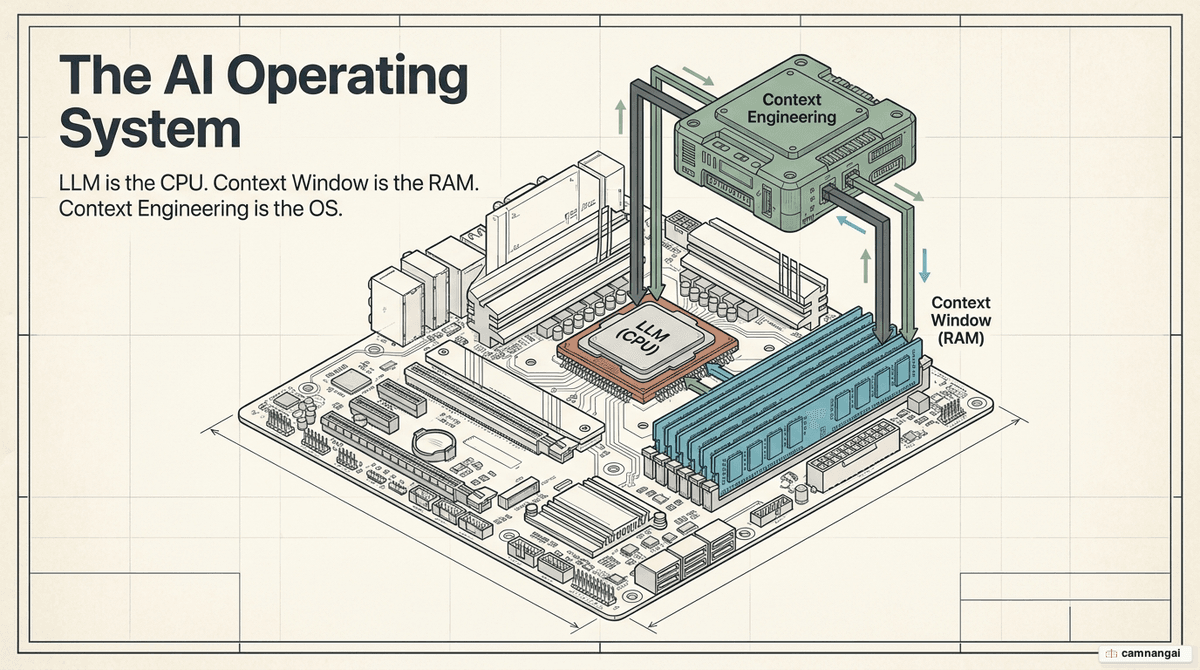
What is context engineering, and how is it different from prompt engineering?
Prompt engineering is a subset of context engineering focused on how to phrase a request. Context engineering is a broader architectural discipline focused on what information the model should possess. In production environments, especially for agents, it manages the iterative, evolving information state across hundreds of turns.
| Dimension | Prompt Engineering | Context Engineering |
|---|---|---|
| Core question | How do I phrase this instruction? | What does the model need to know to get this right? |
| Scope | One-off requests, instruction formatting | The full information system and state management |
| State | Stateless; starts fresh each time | Iterative; manages state over long horizons |
| Primary control | Wording and formatting | Information curation, tool access, and memory |
What are the components that make up an LLM's context?
You must manage seven distinct types of information competing for space within the context window:
- System prompts: behavioral rules, personas, and foundational constraints.
- User input: the specific question or command for the current turn.
- Conversation history: the transcript of prior turns, serving as short-term memory.
- Retrieved knowledge: semantic data pulled from vector databases (RAG).
- Tool definitions: JSON schemas describing available functions and APIs.
- Tool outputs: raw data or results returned from executed tool calls.
- Agent state: internal meta-information like plans, progress markers, or to-do lists.

Why is context a finite resource, not "more is better"?
Handing an LLM massive amounts of data is not a substitute for curation. Transformers rely on an attention mechanism that calculates n² pairwise relationships between all tokens. Doubling your tokens quadruples the compute, so long contexts are slower and more expensive.
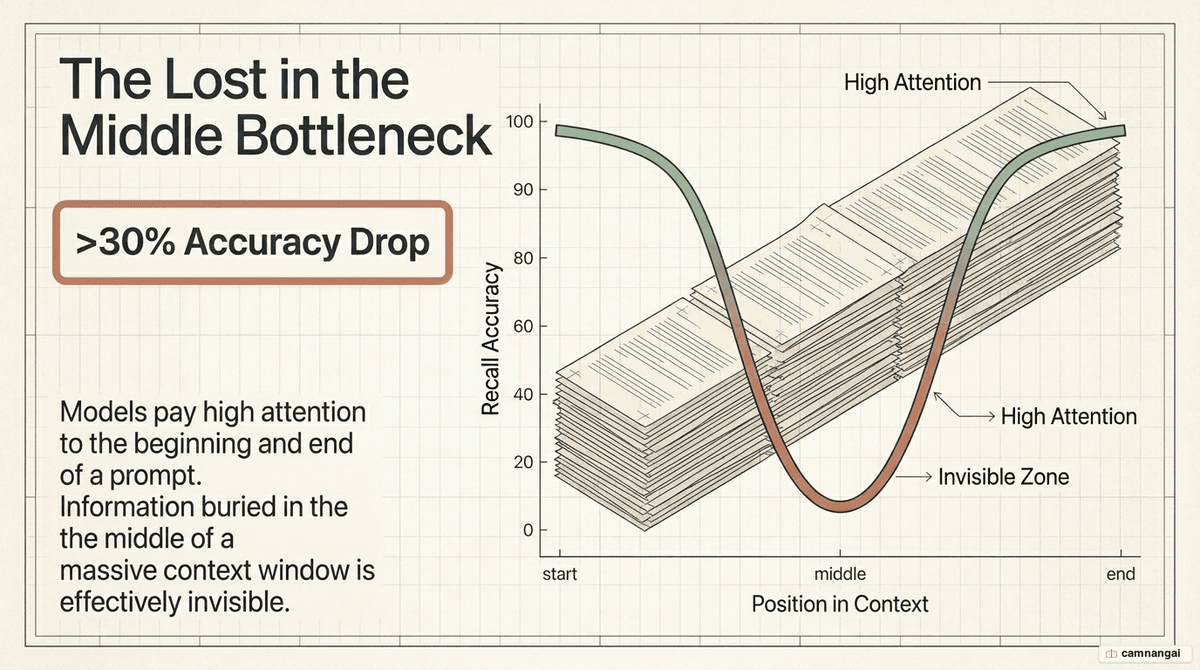
Chroma's 2025 research on 18 frontier models identified "context rot," where model accuracy collapses (for example, from 95% to 60%) once specific length thresholds are exceeded. This performance gradient is driven by the "Lost in the Middle" phenomenon: models show a U-shaped attention curve, recalling information at the start and end of a prompt while suffering a 30% accuracy drop for details in the middle.
This is a structural property of the transformer architecture. Positional encoding methods like Rotary Position Embedding (RoPE) introduce a decay effect where tokens far from the sequence boundaries land in "low-attention zones." Assume that any information not at the prompt's edges is at risk of being ignored.
What are the most common context failure modes?
Context poisoning
A hallucination or tool error enters the model's history and persists, causing later reasoning to build on a false foundation.
- The fix: validate tool outputs before they enter the context, and aggressively prune or compress failed-attempt history so the agent doesn't build on a dead-end debugging trace.
Context distraction
Irrelevant but salient information pulls the model's attention away from the objective, pushing it to repeat past patterns rather than synthesize a new plan.
- The fix: prune irrelevant documents and summarize the conversation history to remove high-token noise.
Context confusion
Too many options — specifically too many tools — overwhelm the model's reasoning. On the GeoEngine benchmark, a quantized Llama 3.1 8B model failed when given 46 tools but succeeded when limited to 19.
- The fix: implement RAG-over-tool-descriptions to surface only the tools relevant to the current task step.
Context clash
Contradictions arise between different context sources, such as a retrieved document conflicting with a system prompt.
- The fix: establish a clear authority ordering (system prompts override history, for example) and use XML tags to delineate sources.
The four core strategies: Write, Select, Compress, Isolate
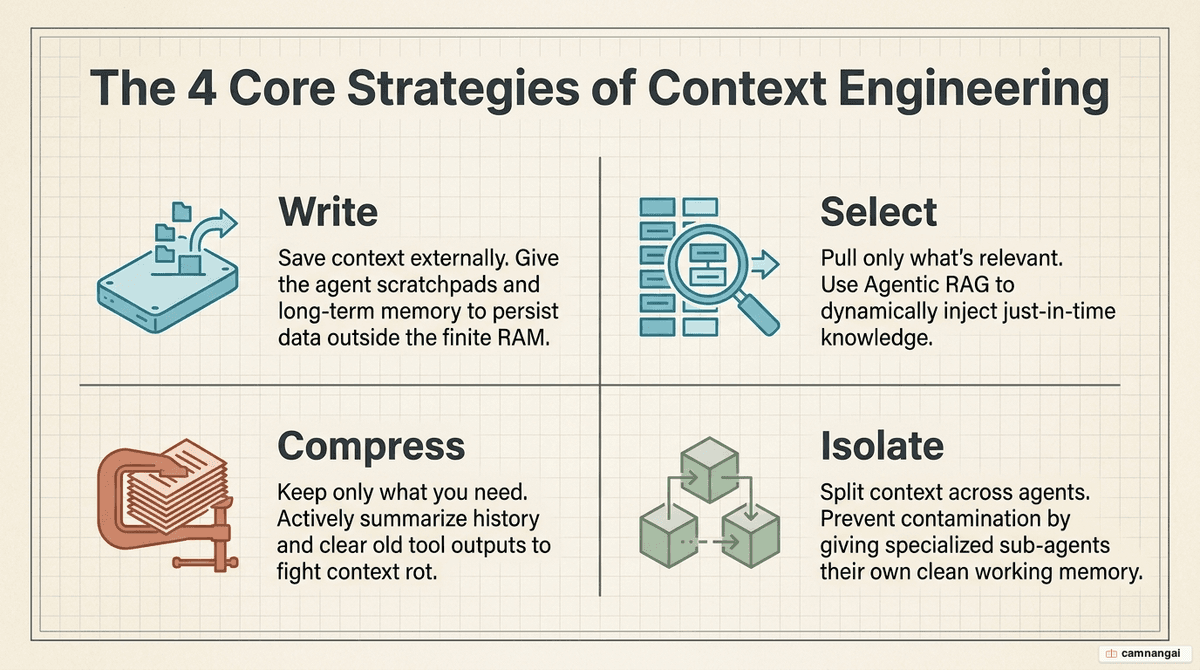
Write: persist information outside the window
Give the agent ways to save facts outside its limited working memory. Use "scratchpads" (like
Anthropic's "think" tool) for intermediate reasoning, and persistent rules files like CLAUDE.md to store
project-specific standing orders the model reads every session.
Select: just-in-time retrieval
Do not load all data upfront. Use agentic RAG, where the model decides what to fetch. RAG-over-tool-descriptions improves tool selection accuracy — one result jumped from 14% to 43% by showing the agent only the definitions it needs for the current step.
Compress: reduce token count
Remove bulk while preserving state. Use "tool result clearing" to drop raw data after the agent has acted on it. Implement an "auto-compact" trigger (as seen in Claude Code) that summarizes the history once the window reaches 95% capacity.
Isolate: multi-agent architectures
Split complex tasks across specialized agents with clean context windows. A researcher agent can process thousands of tokens and return a 1,000-token summary to a lead agent. This isolation prevents context contamination and has demonstrated a 90.2% improvement on research tasks.
How do you get the right information in at the right time?
Implement progressive disclosure: start with snippets or summaries and only fetch deep details if the agent explicitly requests them. This "just-in-time" approach keeps the window from filling with irrelevant data.
You must also account for prefix-caching economics. Inference providers cache the top (prefix) of the context window. Keep stable information like system prompts and tool definitions at the top and you can reuse the cache. Any change to the beginning of the prompt invalidates it, turning a $0.30 per million tokens (cached) call into a $3.00 per million tokens (uncached) one. Always place dynamic history at the bottom.
How do you manage context for long-horizon tasks?
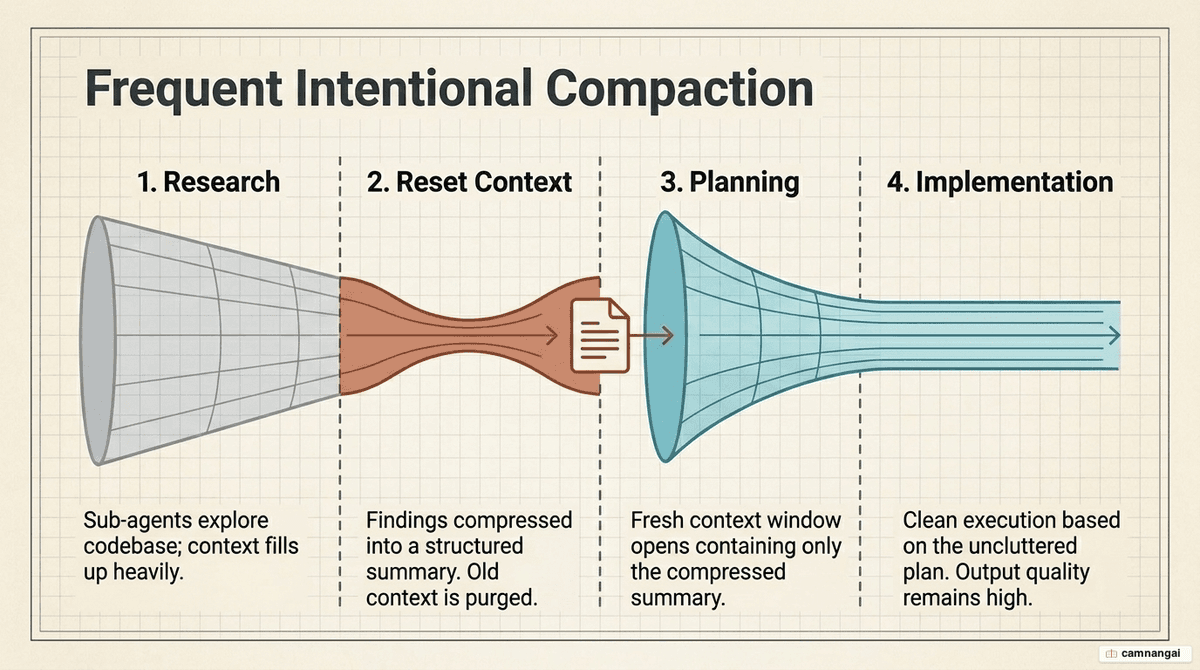
For tasks spanning hundreds of turns, implement the "frequent intentional compaction" workflow:
- Research: the agent explores the environment, producing a compact markdown artifact.
- Context reset: open a fresh context window. The research artifact should take up roughly 15–20% of the new window, effectively clearing 60–80% of the previously used space.
- Planning: the agent creates a plan in this clean window.
- Implementation: the agent executes the plan while maintaining a
progress.mdfile and clearing raw tool outputs as soon as they are no longer required.
How do production frameworks put context engineering into practice?
- Claude Code: uses auto-compaction and the Model Context Protocol (MCP) to load
CLAUDE.mdupfront while navigating the codebase via tools. - Manus: employs KV-cache-aware ordering and "tool masking" — keeping tool definitions in the cached prefix but marking them as unavailable to prevent model confusion.
- Stanford ACE (Agentic Context Engineering): runs a self-improving loop with three roles — the Generator does the work, the Reflector reviews the output, and the Curator updates the agent's playbook. This framework has demonstrated a 10.6% performance gain.
FAQ
What is the difference between a context window and context engineering? The context window is the hardware-like capacity of the model (RAM). Context engineering is the software-like discipline of managing what information occupies that capacity, so the model stays accurate and focused during execution.
When should I move to a multi-agent system? Move to multi-agent architectures when a single agent's context becomes poisoned or distracted by long-running subtasks. Isolation lets each sub-agent keep a clean window, increasing the total tokens the overall system can process reliably.
Does a larger model fix context reliability issues? No. Even frontier models suffer from context rot and "Lost in the Middle" effects. Production reliability is a function of how you structure and prune the context, not simply the parameter count of the underlying model.
References
- A Guide to Context Engineering for LLMs — ByteByteGo
- Context Engineering Clearly Explained (YouTube)
- Context Engineering for Agents (YouTube)
- Context Engineering for Product Builders: The 2026 Operating Manual — Karo Zieminski
- Context Is the New Code — Patrick Debois, Tessl (YouTube)
- Effective Context Engineering for AI Agents — Anthropic
- What Is Context Engineering? — IBM
- What Is Context Engineering? — System Design Newsletter